47
How
the Rasch model IRT latent student ability value is related to the classical
test theory (CTT) PUP quality score (% Right) has not been fully examined. The
following discussion reviews the black box results from Fall8850a.txt (50
students and 47 items with no extreme items) and then examines the final audit
sheets from normal and transformed analyses. It ends with a comparison of the
distributions of latent student ability and CTT quality. The objective is to
follow individual students and items through the process of Rasch model IRT
analysis. There is no problem with the average values.
We
need to know not only what happened but how it happened to fully understand; to
obtain one or more meaningful and usefully views. Fifty students were asked to
report what they trusted using multiple-choice questions. They were scored zero
for wrong (poor judgment), one point for omit (good judgment not to guess and
mark a wrong answer), and two points for good judgment (to accurately report
what they trusted) and a right answer. Knowledge and Judgment Scoring (KJS)
shifts the responsibility for knowing from the teacher to the student. It
promotes independent scholarship rather than the traditional dependency promoted
by scoring a test only for right
marks and the teacher then telling students which marks were right marks (there
is no way to know what students really trust when “DUMB” test scores fall below
90%).
 Winsteps
displays student and item performance in dramatic bubble charts. The Person
& Item chart shows students in blue and items in red. Transposed results (columns
and rows become rows and columns) are shown in an Item & Person chart where
students are red and items are blue (basically everything has been turned
upside down or end over end except the paint job). Blue student 21 with the
highest measure (ability) lands as red student 21 with nearly the lowest
measure when transposed. That is what is done. Why it is done comes later.
Winsteps
displays student and item performance in dramatic bubble charts. The Person
& Item chart shows students in blue and items in red. Transposed results (columns
and rows become rows and columns) are shown in an Item & Person chart where
students are red and items are blue (basically everything has been turned
upside down or end over end except the paint job). Blue student 21 with the
highest measure (ability) lands as red student 21 with nearly the lowest
measure when transposed. That is what is done. Why it is done comes later. A
plot of input/output logit values shows how the process of convergence changes
the locations of latent student abilities (log right/wrong ratio of raw student
scores) and item difficulties (log wrong/right ratio of raw item difficulties)
so they end up as the values plotted on the bubble charts. The ranges of
measures on the input/output charts are the same as on the bubble charts. The
end over end tipping, from transposing, on the bubble charts also occurs on the
input/output charts. Student abilities are grouped as items are treated
individually (items with the same test score land at different points on the
logit scale). When transposed, items difficulties are grouped as students are
treated individually (students with the same test score land at different
points on the logit scale). And, in either case, the distribution being
examined individually has its mean moved to register at the zero logit
location.
A
plot of input/output logit values shows how the process of convergence changes
the locations of latent student abilities (log right/wrong ratio of raw student
scores) and item difficulties (log wrong/right ratio of raw item difficulties)
so they end up as the values plotted on the bubble charts. The ranges of
measures on the input/output charts are the same as on the bubble charts. The
end over end tipping, from transposing, on the bubble charts also occurs on the
input/output charts. Student abilities are grouped as items are treated
individually (items with the same test score land at different points on the
logit scale). When transposed, items difficulties are grouped as students are
treated individually (students with the same test score land at different
points on the logit scale). And, in either case, the distribution being
examined individually has its mean moved to register at the zero logit
location.  The
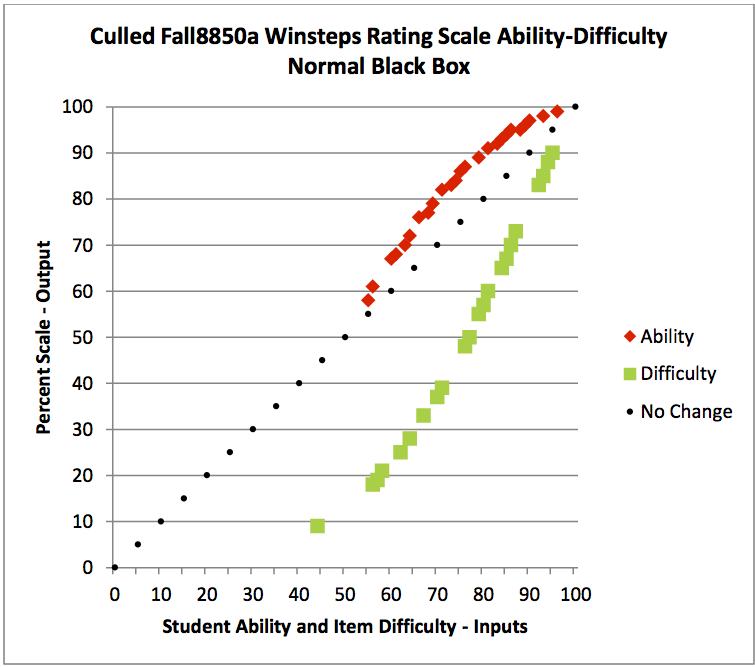
end over end tipping, from transposition, also shows in the normal black box
charts. It is easy to see here that the distribution being held as a reference
shows little change during the process of convergence. The distribution being
examined individually is widely dispersed. Only the highest and lowest
individual values for the same grouped value are shown for clarity. Also a
contour plot line has been added, for clarity, to show how the individual
values would relate to the grouped values if a location correction were made
for the fact that all of these individual values have been reduced by the
distance their mean was moved to put it on the zero logit location during the
process of convergence. In general, the individual values are disbursed about
the contour line. This makes sense as they must add up to their original logit mean
in the above input/output charts.
The
end over end tipping, from transposition, also shows in the normal black box
charts. It is easy to see here that the distribution being held as a reference
shows little change during the process of convergence. The distribution being
examined individually is widely dispersed. Only the highest and lowest
individual values for the same grouped value are shown for clarity. Also a
contour plot line has been added, for clarity, to show how the individual
values would relate to the grouped values if a location correction were made
for the fact that all of these individual values have been reduced by the
distance their mean was moved to put it on the zero logit location during the
process of convergence. In general, the individual values are disbursed about
the contour line. This makes sense as they must add up to their original logit mean
in the above input/output charts. The
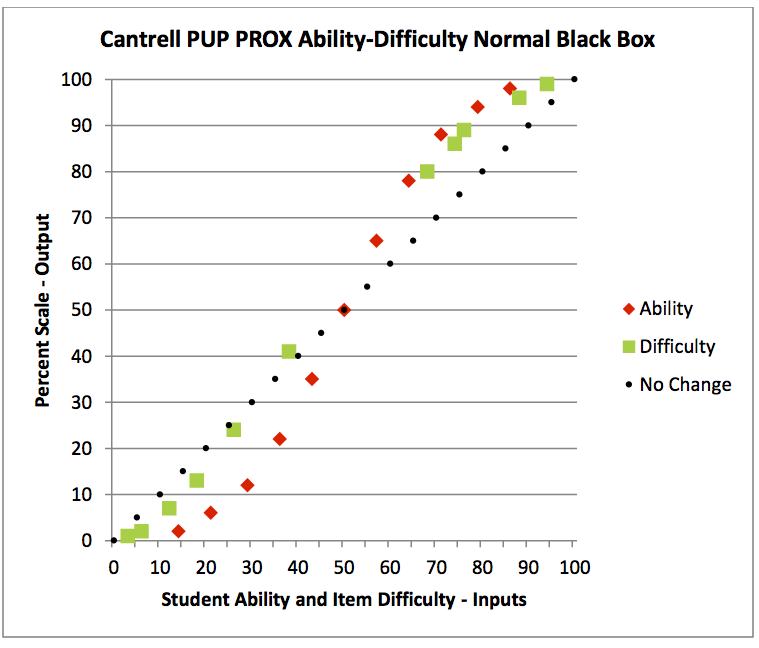
above charts display the values on the final audit sheets for Fall8850a data.
Values from Winsteps Table 17.1 Person Statistics were entered in column four Student
Logit (+) Output. Values from Table 13.1 Item Statistics were entered in column
ten, Item Logit (-) Output. Logit input values were derived from the log
right/wrong and log wrong/right ratios for students and items. Normal input
values are scores expressed as a percent. Normal output values are from the
perfect Rasch model algorithm: exp(logit (+) output)/(1 + exp(logit (+)
output)). Normal output (+) item values come from subtracting Normal (-) values
from 100% (this inverts the normal scale order in the same way as multiplying
values on the logit scale with a -1). One result of this tabling is that
comparable output student ability and item difficult values that are clustered
together add up to 100% (colored on the chart for clarity). This makes sense. A
student ability of 79% should align with an item difficulty with 21% (both with
a location of 1.32 logits).
The
above charts display the values on the final audit sheets for Fall8850a data.
Values from Winsteps Table 17.1 Person Statistics were entered in column four Student
Logit (+) Output. Values from Table 13.1 Item Statistics were entered in column
ten, Item Logit (-) Output. Logit input values were derived from the log
right/wrong and log wrong/right ratios for students and items. Normal input
values are scores expressed as a percent. Normal output values are from the
perfect Rasch model algorithm: exp(logit (+) output)/(1 + exp(logit (+)
output)). Normal output (+) item values come from subtracting Normal (-) values
from 100% (this inverts the normal scale order in the same way as multiplying
values on the logit scale with a -1). One result of this tabling is that
comparable output student ability and item difficult values that are clustered
together add up to 100% (colored on the chart for clarity). This makes sense. A
student ability of 79% should align with an item difficulty with 21% (both with
a location of 1.32 logits).
The
same thing happens when the data are transposed except, as noted in the above
charts, everything is end over end. Column four is now Item Logit (+) Output
from Winstep Table 17.1 Item Statistics and column ten, Student (-) Output, is
from Table 13.1 Person Statistics. Again an item difficulty of 59% aligns with
a student ability of 41% (both with a location of 0.37 logits).

Only
normal values can be used to compare IRT results with CTT results. Sorting the
above charts by logit input values from individual analyses (right side of each
chart) puts the results in order to compare IRT and CTT results. Items 4, 34,
and 36 had the same IRT and CTT input difficulties (73%). They had different
IRT output values and different CTT quality (% Right) values. The item
difficulty quality indicators change in a comparable fashion. (Normally a
quality indicator (% Right) is not calculated for CTT item difficulty. It is
included here to show how both distributions are treated by CTT and IRT
analyses.)
CTT and IRT Quality Indicators
| |||
Method
|
Item (73% Input)
| ||
34
|
4
|
36
| |
CTT
|
83%
|
85%
|
93%
|
IRT
|
44%
|
46%
|
56%
|
Sorting
the transposed analysis by input values groups student abilities. Four students
had the same IRT and CTT abilities (70%). They had different IRT output values
and CTT quality (% Right) indicators. The point is that these quality
indicators behaved the same for student ability and item difficulty and for
normal and transposed analyses.
CTT and IRT Quality Indicators
|
||||
Method
|
Student (70% Input)
|
|||
26
|
37
|
40
|
44
|
|
CTT
|
81%
|
88%
|
88%
|
95%
|
IRT
|
43%
|
51%
|
51%
|
63%
|
IRT + Mean
|
68%
|
76%
|
76%
|
88%
|
These
quality indicators cannot be expected to be the same as they include different
components. CTT divides the number of right answers by the total number of
marks a student makes to measure quality (% Right). The number of right marks
is an indicator of quantity. The test score is a combination of quantity and
quality (PUP uses a 50:50 ratio). Winsteps combines IRT student ability and
item difficulty, with the Rasch model algorithm, during the JMLE analysis into
one expected value, at the same time, it is reducing the output value by the
distance the mean location must be moved to the zero location point:
convergence. CTT only sees mark counts. The perfect Rasch model sees student ability
and item difficulty as probabilities ranging from zero to 1. A more able
student has a higher probability of marking right than a less able student. A
more difficulty item has a lower probability of being marked right than a less
difficult item. This makes sense. A question ranks higher if marked right by more able students. A student ranks higher marking difficult items than marking easier items.

The
above selection of students and items was made from a PUP Table 3c. Guttman
Mark Matrix. The two selections represented uneventful sets of test
performances that seemed to offer the best chance for comparing IRT and CTT.
PUP imports the unexpected values from Winsteps Tables 6.5 and 6.6 to color the
chart. Coloring clearly shows the behavior of three students who never made the
transition from guessing at answers to reporting what they trusted: Order 016,
Order 031, and Order 035 with poor judgment scores (wrong) of 24, 13, and 26.
In
conclusion, Winsteps does exactly what it is advertised to do. It provides the
tools needed for experienced operators to calibrate items for standardized
tests and to equate tests. No pixy dust is needed. In contrast, PUP with
Knowledge and Judgment Scoring produces classroom friendly tables any student
or teacher can use directly in counseling and in improving instruction and
assessment. Winsteps with the Rasch partial credit model can perform the same
scoring as is done with Knowledge and Judgment Scoring. The coloring of PUP
tables provided by Winsteps adds more detail and makes them even easier to use.
There
is no excuse for standardized tests and classroom tests being scored at the
lowest levels of thinking. The crime is if you test at the lowest levels of
thinking you promote classroom instruction at the same level (please see post
on multiple-choice reborn). This holds for essay, report,
and project assessment, as well as, for multiple-choice tests. The Winsteps
Rasch partial credit model and PUP Knowledge and Judgment Scoring offer
students a way out of the current academic trap: learning meaningless stuff for
“the test” rather than making meaningful sense of each assignment that then
empowers the self-correcting learner to learn more. The real end goal of
education is developing competent self-educating learners. It is not to process
meaningless information that is forgotten with each “mind dump” examination.
Personal
computers have been readily available now for more than 30 years. Some day we
will look back and wonder why it took so long for multiple-choice to be scored,
as it originally was before academia adopted it; in such a manner that the
examinee was free to accurately report rather than to continue an academic
lottery used to make meaningless rankings.