46
The normal black box displays IRT results on a normal scale
that can be compared directly to CTT values. The four charts from
Fall8850a.txt, rating scale, culled rating scale, partial credit, and culled
partial credit at not too different from the logit black box charts in the
prior post. The un-culled data set included 50 students and 47 items. The
culled data set included 43 students and 40 items (7 less outlying students and
items each).

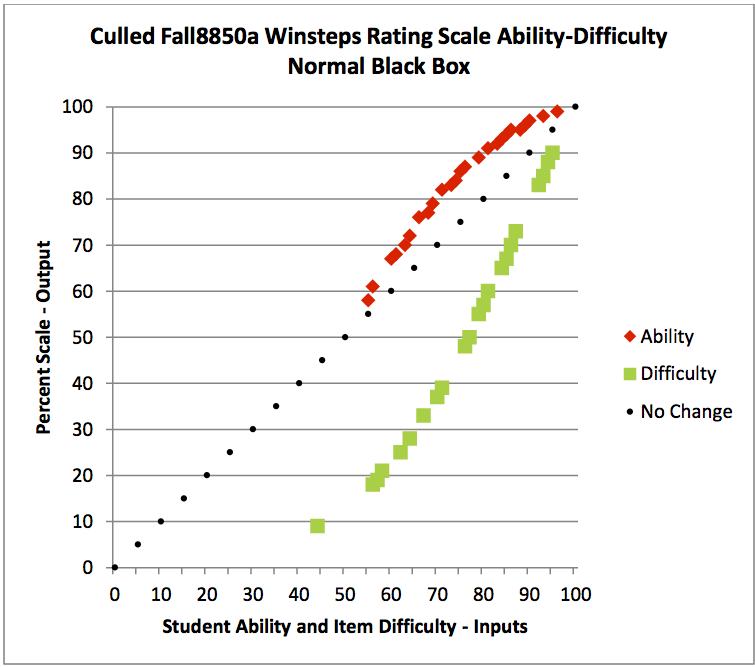
The first three charts show student abilities passing through the 50%, zero logit, point. Failure for this to be the case with culled partial credit was observed in the prior logit black box post, but is very evident in this normal scale chart. The culled partial credit analysis passed through three iterations of PROX rather than two for the other three analyses.


A curious thing was discovered when developing the extended normal values for student abilities. Up to now all extended student ability estimates only involved multiplying the log ratio value of student raw scores by an expansion factor. For the culled partial credit analysis, a shift value had to be included, as is normally done when estimating item difficulty values. A shift value was not needed when estimating student ability values with the un-culled partial credit data set, or any other data set I have examined. The plot of the extended student abilities would not drift away from the no change line without the additional shift of 0.4 logits.
Student scores are used as a standard in non-transposed
analyses. The un-culled data set, using partial credit analysis, will now be
used in a transposed analysis where item difficulties become the standard for the analysis. This may clarify the relationship between
the quality and quantity scores from Knowledge
and Judgment Scoring for each student and the single latent student ability
value from Rasch IRT.












