
The information in Ministep Table 22.1 Guttman Scalogram of Responses has been re-plotted, to the right, into a perfect Guttman pattern. A string of right marks is followed by a string of wrong marks. In this perfect pattern, when a student misses a question on the test, all questions that are more difficult are also missed. The easiest question the student misses sets the student's ability.

Observations more than 0.5 rating points away from their expected category are marked with a letter equivalent: @ = 0, in expected category, and A = 1, just outside of expected category.
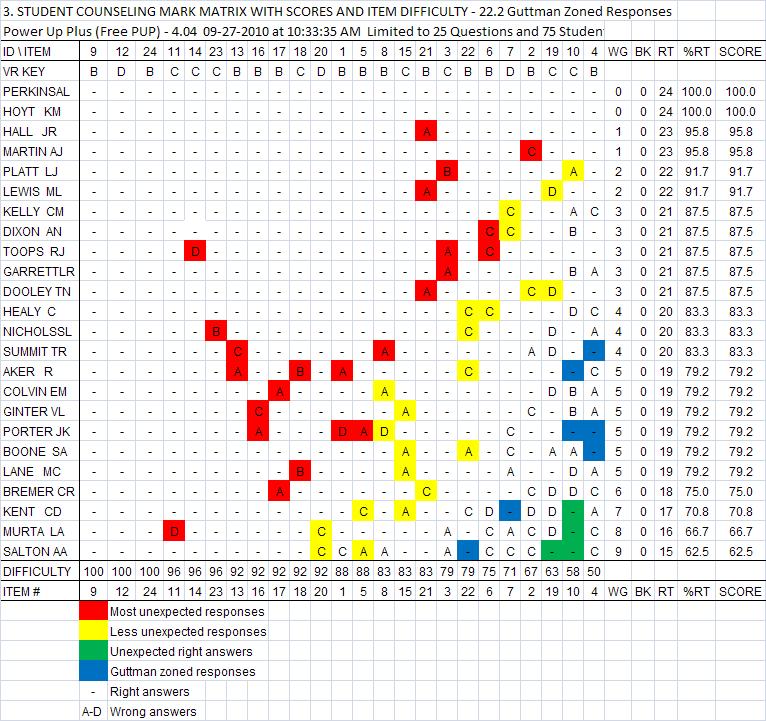
The observations that are outside of their expected category are plotted in blue in this not so perfect world. Each blue mark shows a right answer assumed to be too difficult for that student. Green is both an unexpected and a too difficult right response. Only Item 20 shows a perfect performance pattern.
Otherwise there is a mix of right and wrong marks at the boundary of a student knowing and not knowing, and of a question being marked right or wrong, on PUP Table 3. Table 22.3 Guttman Scalogram of Original Responses is identical, in content, to PUP Table 3. PUP Table 3 is a Guttman Scalogram.








