48
[Chart and table numbers in this post continue from
Multiple-Choice Reborn, May 2015.
This summary seemed more appropriate in this post.]
Before digging further into the relationship between CTT and
IRT, we need to get an overall perspective of educational assessment. When are
test scores telling us something about students and when about test makers. How
the test is administered is as important as what is on the test. The
Rasch partial credit model can deliver the
same knowledge and judgment information needed to guide student develop as
provided by
Power Up Plus.
A perfect educational system has no need for an elaborate method
of test item analysis. All students master assigned tasks. Their record is a
check-off form. There is no variation within tasks to analyze.
Educational systems designed for failure (A, B, C, D, and F,
rather than mastery) generate variation in response to test items from students
with variation in preparation and native ability (nurture and nature).
Further
there is a strongly held belief in institutionalized education that the
“normal” distribution of grades must approximate the normal curve [of error]. Tests are then designed to generate the
desired distribution (rather than let students report what they actually
know and can do). Too many students must not get high or low grades. If so,
then adjust the data analysis (two
different results from the same set of answer sheets).
The last posts to
Multiple-Choice
Reborn make it very clear that CTT is a less complete analysis than IRT.
Parts (CTT) cannot inform us about what is missing to make an analysis whole
(IRT). Only the whole (IRT) can indicate what is missing (CTT). The Rasch IRT
model may shed light on the missing parts not in CTT. The Rasch model seems to
be very accommodating in making test results “look right” judging from its use
in Arkansas and Texas to achieve an almost perfect annual rate of improvement
and to “correct” or reset the Texas starting score for the rate of improvement.
 |
| Table 45 |
A mathematical model includes the fixed structure and the variable
data set it supports or portrays. The fixed structure sets the limits in which
the data may appear. My audit tool (Table 45) contains the data. Now I want to
relate it to the fixed structures of CTT and IRT.
The CTT model starts with the observed raw scores (vertical right mark scale, Table 45a). Item
difficulty is on the horizontal bottom scale. These values stored in the
marginal cells are summed from the central cells containing right and wrong
marks (Table 45a). Test reliability, test SEM and student CSEM are calculated
from the tabled right mark data. This simple model starts with the right mark
facts.
The Rasch model for scores turns right mark facts (scores)
into a natural logarithm of the R/W ratio and a W/R ratio from item right marks
(Table 45b). [ln(ratio) = logit] Winsteps then places the mean of item wrong
marks on the zero point of the score right mark scale. Now student ability =
item difficulties at each measure location. [1 measure = 1 standard deviation
on the logit scale]
The Rasch model for precision is based on probabilities generated from the two
sets of marginal cells (score and difficulty, blue, Table 45b). Starting with a generalized probability
rather than the pattern of right and wrong marks makes IRT precision
calculations different (more complete?) from CTT. The peak of the curve for
items is arbitrarily set at the zero location by Winsteps (Chart 100). This also
forces the variation to zero (perfect precision) at this location. [Precision
will be treated in the next blog.]
I
created a Rasch model for a test of
30 items to summarize the treatment of student scores (raw, measures and
expected).
 |
| Chart 93 |
 |
| Chart 94 |
 |
| Chart 95 |
Chart 93 shows a normal distribution (BIONOM.DIST) of raw
scores for a 30 item test with an average score of 50% and of 80%. The
companion normal (right count)
distribution for item difficulty (Chart 94) from 30 students looks the same.
This is the typical classroom display.
The values in Chart 94 were then flipped horizontally. This
normal (wrong count) distribution
for item difficulty (Chart 95) prepares the item difficulty values to be
combined with scores onto a single scale.
 |
| Chart 96 |
 |
| Chart 97 |
I created the perfect Rasch model curve for a 30 item test
in two steps. The Rasch model for scores (solid black, Chart 96) equals the
natural logarithm of the ratio of right/wrong [ln(R/W)] in Chart 93. Flipping
the axes (scatter plot) produced the traditional appearing Rasch model Chart 97.
This model is for any test of 30 items
and for any number of students.
 |
| Chart98 |
Chart 98 shows the perfect Rasch model: the curve, and score
and difficulty, for a test with an average score of 50%. The peak values for score and
difficulty are at 15 items or 50% at zero measures. This of course never
happens. The item difficulties generally have a spread of about twice that of
student
scores. (See Table 46 in Multiple-Choice Reborn, and the related charts
for 21 items.)
 |
| Chart 99 |
Throughout this blog and
Multiple-Choice Reborn the maximum
average test score that seems appropriate for the Rasch model, as well as
comments from others, has been near 80%. Chart 99 shows
right mark score and
wrong
mark item values as they are input into the Rasch model. They balance on
the zero point.
 |
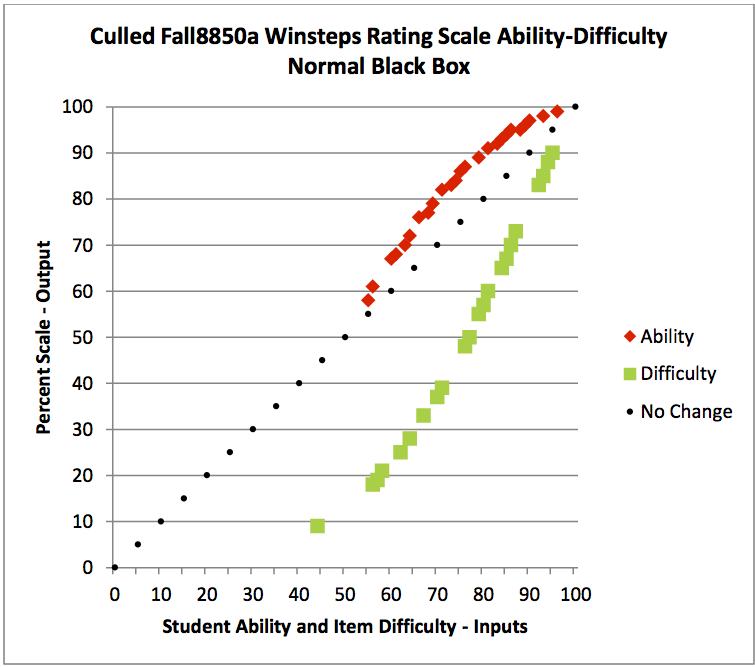
| Chart 100 |
Next, Winsteps, relocates the average test item value (red
dashed) to the zero test score location (green dashed, Chart 100). Now item
difficulty and student ability are equal at each and every location on the
measures scale. I have reviewed several ways to do this for test items scored
right or wrong:
graphic,
non-iterative
PROX and
iterative
PROX.
In a perfect world the transforming line, IMHO, would be a
straight line. Instead it is an S-shaped wave (a characteristic curve) that is
the best psychometricians can do with the number system used. Both are used in
Winsteps Table 20.1. Scores as measures are transformed into expected student
scores (Winsteps Table 20.1). In a perfect world expected scores would equal
raw scores; there would be no difference between CTT and IRT score results. [For practical purposes, the space between -1 measure and +1 measure
can be considered a straight line; another reason for using items with
difficulties of 50%.]
 |
Chart 101
|
Addendum: Billions of dollars and classroom hours have been wasted in a
misguided attempt to improve institutionalized education in the United States
of America using traditional forced-choice testing. Doing more of what does not work, will not make it work. Doing more
at lower levels of thinking will not produce higher levels of thinking results;
instead, IMHO, it makes failure more certain (forced-choice at the bottom of
Chart 101). Individually assessing and rewarding higher levels of thinking does
produce positive results. Easy ways to do this have now existed for over 30
years! Two are now free.