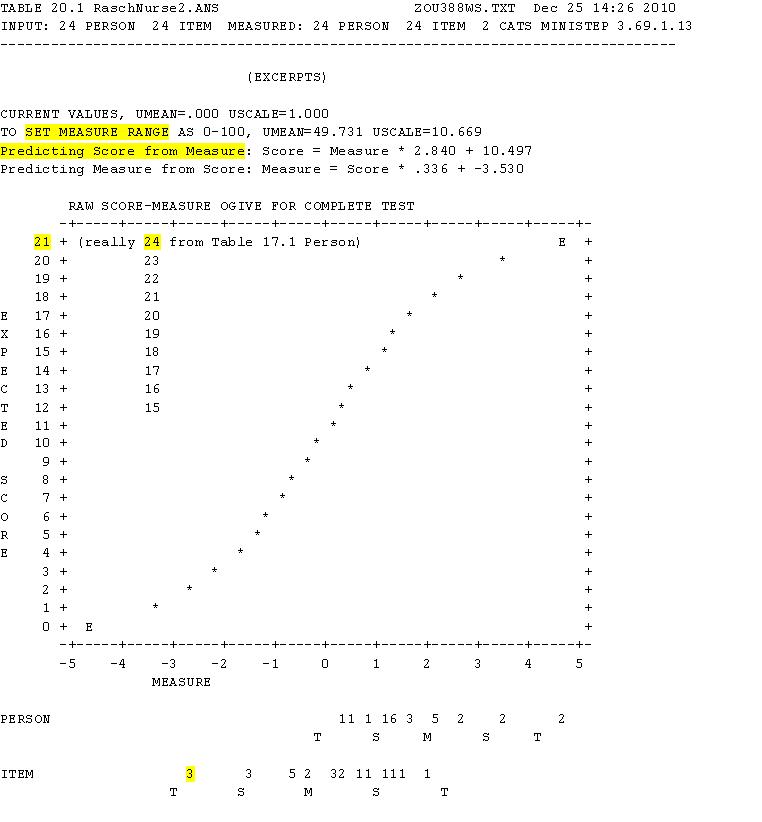
The test characteristic curve (TCC) is used to relate one test with another. Ministep Table 20.1, Raw Score-Measure Ogive for Complete Test, displays the TCC and the expected raw scores when student ability measures equal item difficulty measures.
 The TCC results from Winsteps processing observed student test scores into estimated measures and then predicting expected student raw scores.
The TCC results from Winsteps processing observed student test scores into estimated measures and then predicting expected student raw scores. Table 20.1 assists in predicting raw scores from estimated measures and the reverse (mapping). This relationship is fully linear rather than an ogive. Values are also presented to assist in setting the range of scaled scores, of replacing the unit for measures (the logit) with arbitrary values.
Winsteps has a problem with questions and students who generate perfect scores. The TCC in Table 20.1 terminates with 21 rather than 24 as all students marked three items correctly. Perfect scores are rare when using several hundred answer sheets. Other factors influence the TCC and it use.
Winsteps uses “fit” to describe how well persons and items match the Rasch model requirements. PUP uses “fitness” to describe how well the test matches student preparation. The fitness value is also called the average student educated guessing score. It has a value of 100% on a perfect test (a check list of what students have mastered). Fitness has a value of 25% on a 4-option multiple-choice test where all options are about equally marked. This would be a very difficult test, requiring considerable guessing when forced-choice scoring.

The average student educated guessing score ranged between 38.7% and 55.8%, on PUP Table 5, with an average of 47.8%. About half of the answer options on the test could be discarded by students functioning at higher levels of thinking before selecting their “best” right answers.
Guessing is not a part of the Rasch model. With test fitness near 50%, and an average test score of 84%, guessing had little effect on the scores of this test. Guessing can have a marked effect on test scores when test fitness drops to the design level of 25% for 4-option questions. At this point the Rasch model and the three-parameter (3-P) IRT model, that includes guessing, diverge widely.
Forced-choice or guess testing requires a mark on each question. Knowledge and Judgment Scoring (KJS) only requires a mark to use a question as a means of reporting what a student actually knows or can do (what is known and the judgment to correctly use what is known). The Rasch model labors under the requirement for students to guess just as with traditional, right mark, scoring. The partial credit Rasch model may serve KJS better.










